Transparentna migracja usług WWW i poczty
bez zmiany haseł, bez przestojów i bez bólu użytkowników
(z HAProxy, węzłem zapasowym i rozbudową DC po drodze)
Migracja infrastruktury nie powinna być wydarzeniem dla użytkownika. Jeżeli ktoś dzwoni, że „coś się zmieniło” – to znaczy, że coś poszło nie tak.
Ten opis dotyczy realnej migracji usług WWW i poczty pomiędzy serwerami i lokalizacjami, przeprowadzonej bez resetu haseł, bez przerw w dostępie i bez informowania użytkowników, a przy okazji połączonej z rozbudową DC o:
- węzeł zapasowy,
- centralne backupy,
- HAProxy jako punkt styku ze światem.
Bez teorii. Bez „best practices z prezentacji vendora”. Same rzeczy, które faktycznie zadziałały – oraz kilka, które wywróciły się po drodze i nauczyły nas, czego nie robić drugi raz.
Założenia – co MUSIAŁO się udać
Na wejściu były twarde warunki:
- Użytkownicy nie zmieniają haseł, nie podają ich ponownie – my ich nie znamy i znać nie chcemy.
- Brak downtime – WWW i poczta działają przez cały czas migracji.
- Migracja wykonywana w godzinach biznesowych.
- Nowa infrastruktura musi oferować więcej niż stara – nie tylko „to samo gdzie indziej”.
- Nie „przenosimy serwera”, tylko:
- dokładamy backup node,
- porządkujemy backupy i centralizujemy je,
- wpinamy HAProxy jako front.
Architektura po migracji (w skrócie)
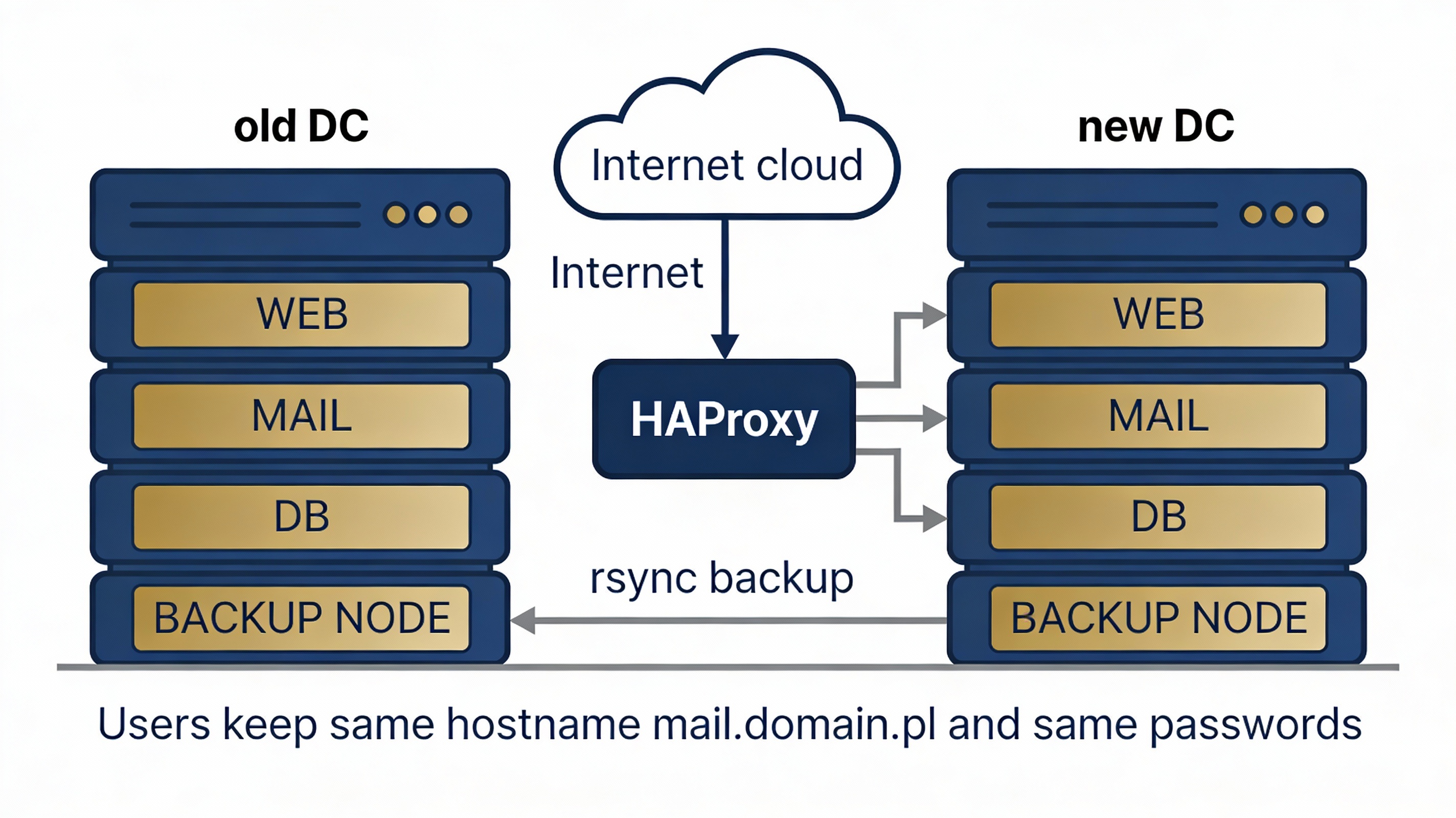
HAProxy – jedyny punkt wejścia (WWW + SMTP/IMAP/POP3).
Serwer WEB – hosting stron + centralny backup baz danych.
Serwer MAIL – obsługa poczty.
Backup node 1 – węzeł zapasowy + możliwość przywracania wybranych danych.
Backup node 2 – węzeł zapasowy + możliwość przywracania wybranych danych.
Użytkownik dalej używa tych samych haseł, ma ten sam adres mail.domain.pl,
widzi tę samą stronę WWW.
Różnica jest wyłącznie po naszej stronie.
Projekt i kamienie milowe – czyli jak to zrobiliśmy, że nikt się nie zorientował
Krok 1: WWW – dlaczego WordPress wyleciał
Analiza logów była brutalnie szczera: ~90% ruchu to boty, crawlery i ataki na WordPressa (wp-login.php, xmlrpc.php, losowe *.php – dzień w dzień). Strona nie potrzebowała CMS‑a, nie potrzebowała bazy danych – miała sprzedawać kontakt, nie wtyczki.
Decyzja: WordPress OUT. Proste PHP + HTML, brak SQL, brak uploadów, minimalna powierzchnia ataku. Efekt: spadek zużycia CPU i RAM, „uciszone” logi, ataki przestały mieć sens. To był pierwszy krok do transparentnej migracji – bo WWW przestało być problemem.
Krok 2: Backup baz – jeden punkt prawdy
Backup wykonujemy raz, a następnie dystrybuujemy go tam, gdzie jest potrzebny. Na serwerze WWW powstaje pełny dump wszystkich baz + osobny dump wybranych baz aplikacyjnych (WWW). Dlaczego rozdzielnie?
Bo serwery mają różne role i różne wersje MariaDB – nie wolno przywracać tabel systemowych na inną wersję. Finalnie jeden katalog z backupem baz = jeden plik + jedna dystrybucja rsync do reszty środowiska.
Krok 3: Restore selektywny – nie wszystko wszędzie
Kluczowy moment: na Oracle Linux pełny restore zadziałał. Na Ubuntu 22.04,
gdzie MariaDB była w wersji 10.6, a backup z 10.5, przywrócenie tabel systemowych
rozwaliło aplikację biznesową – brak kolumn w mail_domain,
błędy typu Unknown column 'local_delivery'.
Wniosek: backup ≠ restore. Restore musi być dopasowany do roli serwera. Rozwiązanie: na węźle zapasowym przywracamy wyłącznie bazy aplikacyjne, bazy systemowe (mysql, performance_schema, sys) są nietykalne. To zamknęło temat baz.
Krok 4: Migracja poczty bez resetu haseł
Najważniejszy punkt całej operacji. Założenie: nie znamy haseł, nie zmieniamy haseł, użytkownik nie ma nic zauważyć. Ta sama wersja aplikacji, ten sam OS, ten sam format Maildir i spójny stack pocztowy.
Na nowym serwerze przygotowaliśmy skrzynki, a katalog /var/vmail
został przeniesiony rsynciem z opcjami --numeric-ids -Aax.
Przenieśliśmy bazę aplikacji mailowej z użytkownikami, zmieniliśmy DNS.
Efekt: hasła zostały, foldery zostały, klienci pocztowi nie zauważyli żadnej zmiany.
Jedyny incydent? Fail2ban, który zablokował rsync – klasyka. Odblokowane i jazda dalej.
Krok 5: Certyfikaty SSL – gdzie naprawdę kończy się TLS
Po zmianie DNS klienci pocztowi zgłaszali „niezaufany certyfikat”. Dlaczego?
Bo TLS kończy się nie tam, gdzie fizycznie stoi serwer poczty, tylko tam,
gdzie wskazuje DNS (np. mail.domain.pl), a w naszym przypadku
ruch był terminowany na HAProxy.
W praktyce oznaczało to:
- generowanie certyfikatu na węźle frontowym,
- dystrybucję (rsync) certyfikatu na serwer pocztowy,
- spójność certów we wszystkich punktach, gdzie kończy się TLS.
Tak – rsync certyfikatów. Tak – akceptowalne. Tak – działa.
Efekt końcowy
Użytkownik:
- nie zmienił hasła,
- nie zmienił konfiguracji klienta poczty,
- nie odczuł żadnego przestoju.
Administrator:
- ma backup node,
- ma HAProxy jako centralny front,
- ma uporządkowane, centralne backupy,
- ma możliwość selektywnego restore, dopasowanego do roli serwera.
I co najważniejsze – migracja była przezroczysta. A taka migracja jest jedyną poprawną. Nie każda migracja to „lift & shift”. Backup i restore to dwa różne problemy. Poczta da się migrować bez resetu haseł. Certyfikat jest tam, gdzie kończy się TLS, a nie tam, gdzie stoi usługa. Jeżeli użytkownik nic nie zauważył – wygrałeś.