Stabilna i bezpieczna infrastruktura IT dla małej firmy
od chaosu do porządku w kilka tygodni
Punktem wyjścia była słaba kondycja infrastruktury, rosnące koszty utrzymania serwerów on-premise oraz coraz droższa chmura po zmianach licencjonowania VMware w latach 2025–2026. Do tego dochodził silnie rosnący ruch, brak rozproszonego backupu, pojedynczy serwer WWW jako one point of failure, podstawowy monitoring usług i logów oraz skomplikowana obsługa certyfikatów zarówno dla klientów, jak i samej firmy.
Firma rozwijała się szybko, ale infrastruktura nie nadążała – potrzebna była stabilna i skalowalna platforma do pracy dla globalnego, rozproszonego zespołu i klientów z całego świata.
Cel projektu
Celem projektu było:
- wybór alternatywnego dostawcy usług cloudowych,
- przeniesienie infrastruktury w możliwie najkrótszym czasie,
- pełna transparentność dla użytkowników (bez przestojów, bez wymuszonych zmian haseł),
- zwiększenie automatyzacji i autonomii systemów.
Projekt jest naturalnym rozwinięciem opisanej wcześniej realizacji „Transparentna migracja usług WWW i poczty bez zmiany haseł, bez przestojów i bez bólu użytkowników”, gdzie skupialiśmy się na samej migracji.
Discovery – fundament transformacji
Pierwszym krokiem był szczegółowy IT discovery:
- pełna inwentaryzacja domen, certyfikatów, kont pocztowych i usług,
- analiza infrastruktury technicznej, połączeń VPN oraz obciążenia dziennego i godzinowego,
- identyfikacja braków w backupie, monitoringu i bezpieczeństwie.
Discovery potraktowaliśmy jak klasyczną fazę planowania – około 80% wysiłku poszło w analizę i plan, 20% w samą egzekucję. To właśnie ten etap zadecydował o tym, że transformacja zakończyła się sukcesem.
Wybór chmury – dlaczego Kamatera
Analizowaliśmy praktycznie wszystkich dużych dostawców: AWS, Azure, IBM Cloud, Alibaba Cloud, Google Cloud oraz kilku mniejszych graczy. Każdy miał swoje plusy i minusy, więc decyzję podparliśmy analizą SWOT oraz klasycznym trójkątem zarządzania projektem (zakres–czas–koszt).

Finalnie wybraliśmy izraelskiego dostawcę Kamatera, ponieważ połączył dojrzałe narzędzia, solidną infrastrukturę, przystępne ceny i prostotę konfiguracji. Z perspektywy czasu był to dobry wybór, choć po drodze nie obyło się bez kilku naturalnych eskalacji.
Architektura hybrydowa zamiast „all‑in cloud”
Nowa infrastruktura została zbudowana w modelu hybrydowym: chmura publiczna + lokalne datacenter on-premise połączone bezpiecznymi tunelami VPN, z HAProxy jako centralnym punktem styku dla ruchu WWW i poczty.
Dlaczego hybryda?
- większe bezpieczeństwo i poufność danych,
- elastyczność – prace serwisowe można prowadzić „na żywo”, bez częstych okien serwisowych,
- lepsza kontrola kosztów – chmura jest świetna, ale nie jest za darmo.
Żeby chmura była realnie opłacalna:
- uporządkowaliśmy i odchudziliśmy środowisko (dekomisja niepotrzebnych usług),
- oddzieliliśmy produkcję od środowisk testowych,
- skonsolidowaliśmy kilka narzędzi na mniejszej liczbie serwerów – różne aplikacje pracują o różnych porach dnia, a serwery są równomiernie wykorzystywane przez całą dobę.
Plan migracji – kamienie milowe i testy
Na bazie raportu discovery powstał szczegółowy plan migracji określający:
- co przenosimy i w jakiej kolejności,
- jakie są zależności między usługami,
- jakie testy wykonujemy po każdym kamieniu milowym.
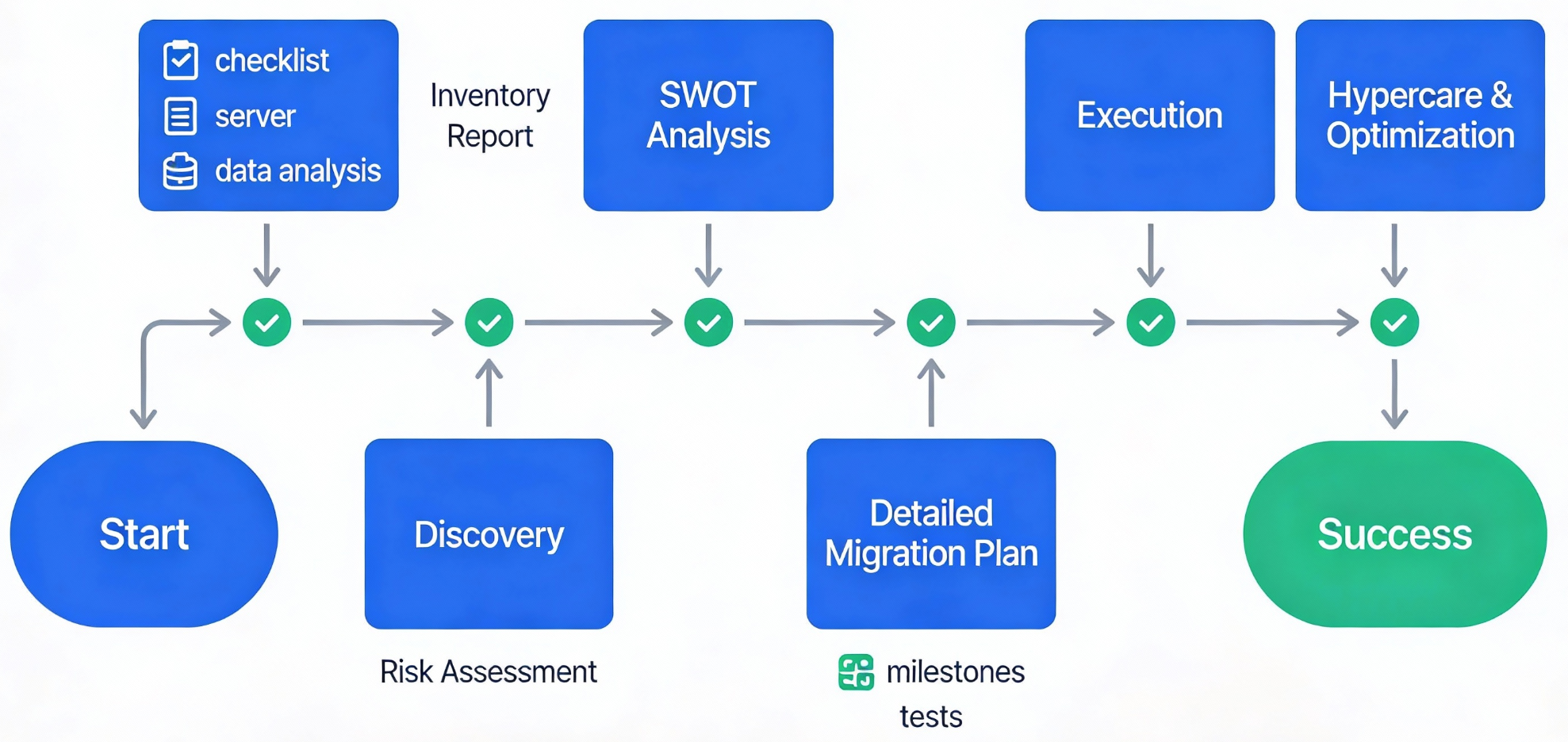
Każdy etap kończył się testami, które dawały pewność, że zmiana nie spowoduje przestoju ani problemów dla użytkowników. Założenie było proste – migracja ma być dla biznesu niewidoczna.
Przygotowanie nowej infrastruktury
Po wyborze dostawcy samo zbudowanie nowej infrastruktury było już stosunkowo proste. Narzędzia cloud były na tyle zaawansowane, że w ciągu kilku godzin udało się zbudować odpowiednią infrastrukturę gotową do migracji. Głównym elementem była warstwa HAProxy oraz odpowiednie technologie VPN łączące chmurę z lokalnym datacenter on-premise.
Egzekucja – bezpieczne przełączenie
Realizacja planu opierała się na ścisłym zarządzaniu ryzykiem (także tym pozytywnym), częstych testach pośrednich, doświadczonym zespole inżynierów oraz wsparciu nowoczesnych technologii – w tym nowoczesnych modeli językowych, potocznie nazywanych sztuczną inteligencją (AI).
Efekt? Mniej zgłoszeń od użytkowników, szybsze i bardziej wydajne usługi oraz mniej zakłóceń i „szumu” ze środowiska.
Optymalizacja i Hypercare
Unikalny czas zaraz po wdrożeniu rozpoczął się tuż po przeniesieniu systemu na nową infrastrukturę. Wyjście na świat zabezpiecza Fortinet, dalej ruch trafia do publicznej chmury z HAProxy i zapasowymi datacenter z balansowaniem ruchu.
Środowisko wspiera rozproszony backup oraz disaster recovery, szybki VPN, superwydajne i bezpieczne serwery on-premise z konteneryzacją Docker oraz FreeBSD jails. Monitoring opiera się na Nagios, rozszerzonym o analizę systemu przez autorski model AI.
To wszystko w określonym czasie i budżecie pozwoliło ponad czterokrotnie zwiększyć wydajność usług w porównaniu z poprzednią infrastrukturą. Optymalizacja – czyli w praktyce Business As Usual – trwa cały czas, a monitoring wydajności i jakości usług jest mocno wspierany przez inżynierów oraz narzędzia AI, tak aby maksymalizować wydajność i stabilność, a jednocześnie obniżać koszty tam, gdzie jest to możliwe przy kontrolowanym ryzyku.